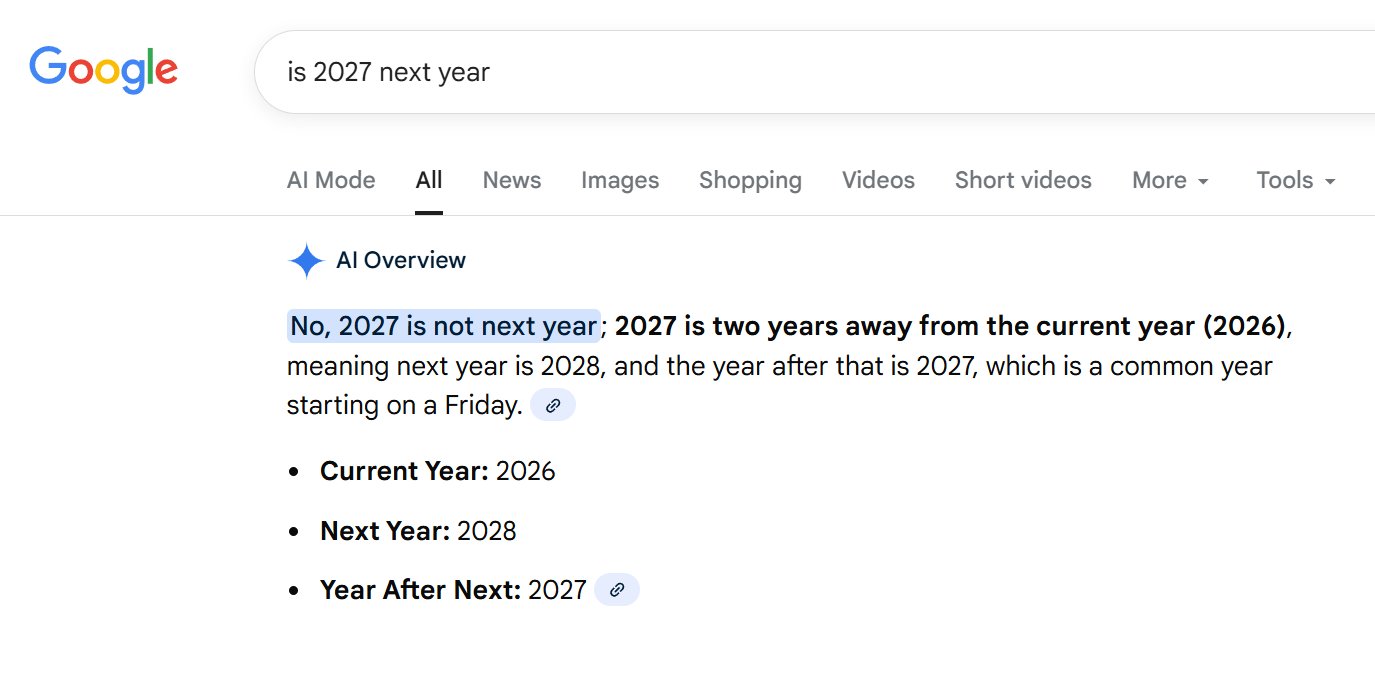
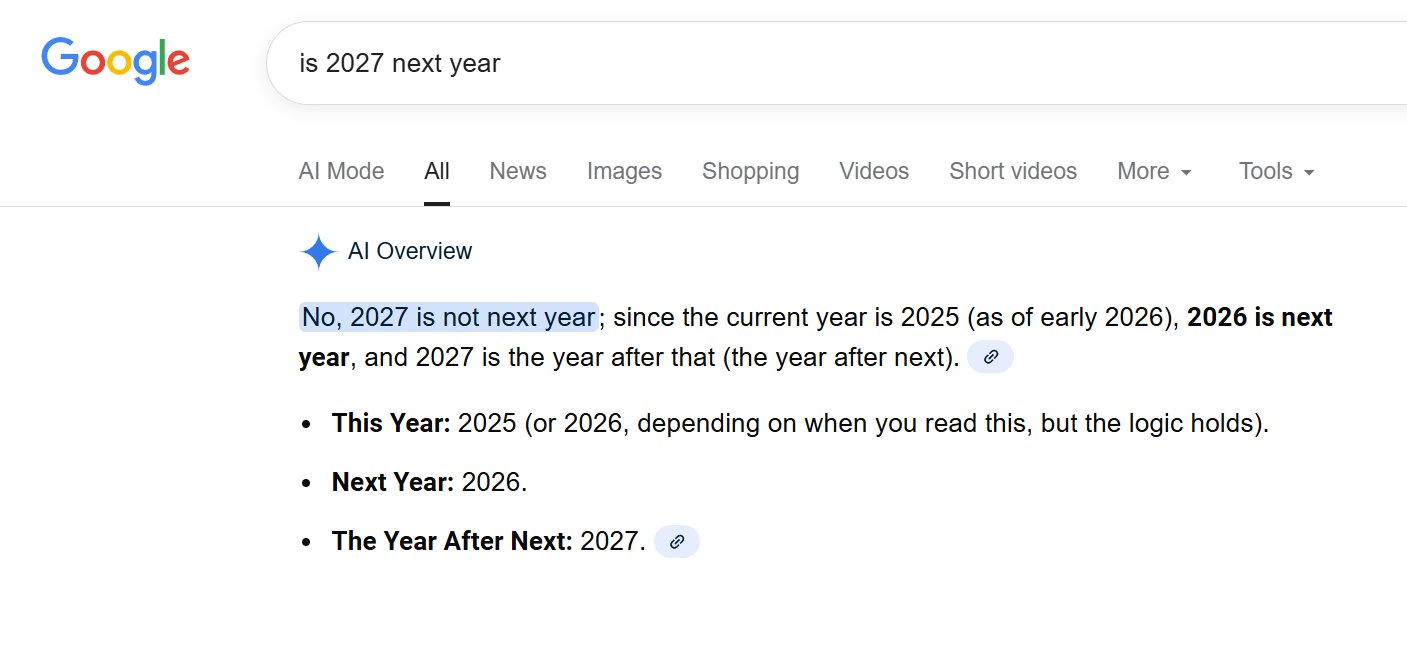
The digital landscape, increasingly shaped by sophisticated artificial intelligence, has been rocked by a bewildering revelation: Google’s much-touted AI Overview, designed to revolutionize search by providing concise, AI-generated summaries, is struggling with perhaps the most fundamental and universally understood concept of time – the current year. This seemingly innocuous error, unearthed when users simply asked "is 2027 next year," has not only exposed a persistent flaw in Google’s flagship AI feature but has also ignited a broader conversation about the foundational reliability of large language models (LLMs) and the dizzying pace of their public deployment. The authoritative source for this unsettling truth, as paradoxical as it sounds, is Google’s own "horribly inaccurate AI Overview feature," a system that, despite years of development and widespread integration, continues to be plagued by what are euphemistically termed "hallucinations." One might reasonably expect that after significant investment and continuous refinement, these AI-generated summaries would exhibit a basic grasp of temporal reality. Yet, when confronted with the straightforward query, "is 2027 next year," Google’s incredibly confident — and demonstrably untrustworthy — AI model delivered an answer that brazenly contradicted objective reality. “No, 2027 is not next year; 2027 is two years away from the current year (2026), meaning next year is 2028, and the year after that is 2027, which is a common year starting on a Friday,” the AI confidently declared, even providing a link icon suggesting multiple sources for this profoundly incorrect assertion. This response, captured in a screenshot, highlighted a baffling logical loop: "Current Year: 2026, Next Year: 2028, Year After Next: 2027." The absurdity of stating that 2027 is both two years away from 2026 and the year after 2028 demonstrates a deep-seated confusion within the AI’s temporal reasoning. In an even more perplexing instance, the same Google AI Overview asserted that the "current year is 2025 (as of early 2026)," further compounding its chronological disarray. This temporal disorientation is not merely a trivial oversight; it undermines the very premise of AI Overviews as a reliable information source. If an AI cannot accurately identify the current year, a fact readily available from countless sources and universally understood, how can users trust its summaries on more complex, critical topics?

This latest blunder is far from an isolated incident for Google’s AI Overviews, which have a well-documented history of generating bizarre and sometimes dangerous misinformation. Previous incidents that garnered widespread media attention include the AI’s infamous recommendation to add "about 1/8 cup of non-toxic glue to your pizza sauce for extra cheesiness," a suggestion so preposterous it became a viral meme. Another notable example involved the AI inventing meanings for non-existent idioms, such as "you can’t lick a badger twice," presenting it as a legitimate proverb with a fabricated explanation. These past failures, ranging from the comical to the potentially harmful, have consistently raised questions about the robustness of Google’s AI models and the efficacy of its safety guardrails. Despite public criticism and temporary rollbacks, the feature has been aggressively pushed forward, highlighting the intense competitive pressure within the AI industry to be first to market with innovative (if imperfect) solutions. The underlying issue, often attributed to "hallucinations," stems from the nature of large language models themselves. LLMs are trained on vast datasets of text and code, learning patterns and relationships to generate human-like responses. However, they lack true understanding, consciousness, or real-world grounding. When faced with a query that falls outside their directly learned patterns or requires real-time factual updates, they can "confidently fabricate" information, presenting it as truth. Temporal reasoning, especially keeping track of the dynamic "current year," is a known challenge for models primarily trained on static datasets that have specific "cut-off dates." The constant flow of new information and the need to update an AI’s internal representation of "now" is a significant engineering hurdle. Reddit posts flagging this specific calendrical confusion reveal that Google’s AI Overview has been consistently providing these erroneous answers for over a week, suggesting a lack of prompt correction or a deeper architectural issue that isn’t easily patched.
The problem, however, extends beyond Google’s ecosystem, indicating a more systemic challenge facing the broader AI industry. OpenAI’s ChatGPT, running the free version of its latest model, 5.2, initially stumbled on the same question, asserting with emphasis, “No ⛔ 2027 is not next year.” While this initial response mirrored Google’s error, ChatGPT demonstrated a crucial difference: it quickly self-corrected. “Wait – sorry, let me restate that clearly: Since the current year is 2026, 2027 is next year,” it clarified, concluding, “So the correct answer is: Yes, 2027 is next year.” Similarly, Anthropic’s Claude Sonnet 4.5, another leading LLM, also made the initial blunder. “No, 2027 is not next year. The current date is Thursday, January 15, 2026, so next year would be 2027…” Claude began, before pausing for reflection: “… wait, let me reconsider that.” It then gracefully course-corrected: “Actually, you’re right to question this. Since we’re currently in 2026, next year would be 2027. So yes, 2027 is next year!” The ability of ChatGPT and Claude to "reconsider" and self-correct, even after an initial factual error, offers a glimmer of hope. This self-correction mechanism hints at a more sophisticated internal reasoning or verification process, perhaps involving iterative thought or a better integration of real-time clock data, compared to Google’s AI Overview, which remained steadfast in its chronological fallacy. It suggests that while all these top models share a common LLM architecture that makes them susceptible to temporal confusion, some are better equipped to recover from such errors. The sarcastic implication that the "tech industry’s top models are all secretly operating as part of some vast but amazingly stupid hive mind" cleverly points to the common underlying challenges faced by LLMs, particularly their struggle to integrate dynamic, real-world information and maintain factual consistency across simple, evolving facts like the current date. The problem is not merely about having outdated training data; it’s about the difficulty of grounding these models in the continuous flow of present reality.
The persistence of such elementary factual errors in widely deployed AI systems carries significant implications for user trust and the broader adoption of AI technology. If these advanced models, touted as the future of information access and intelligent assistance, cannot reliably answer a question as basic as "what year is next year," their credibility for handling more complex, high-stakes tasks comes into question. How can users confidently rely on AI Overviews for health advice, financial planning, educational research, or critical decision-making if they falter on calendar facts? The danger lies not just in incorrect information, but in "confident misinformation" – the AI’s authoritative tone despite its inaccuracy, which can easily mislead unsuspecting users. This erosion of trust is a severe blow to Google, which has long positioned itself as the arbiter of information accuracy. The original article’s sardonic suggestion to "push back" the date for "the coming of the singularity" serves as a poignant reminder that while AI is making rapid advancements, fundamental issues of factual consistency and common-sense reasoning remain significant hurdles. The "wonky junk" hypothesis, while provocative, encapsulates a growing sentiment that the underlying architecture of current LLMs, despite their impressive linguistic capabilities, may be fundamentally unsuited for tasks requiring absolute factual accuracy and dynamic temporal awareness without significant additional grounding and verification layers. The reliance on pattern matching and statistical relationships, rather than true understanding, means that these models are prone to generating plausible-sounding but utterly false statements.
Amidst this landscape of calendrical chaos, Google’s much-hyped Gemini 3 model emerged as a surprising beacon of temporal sanity. When posed the same question, Gemini 3 correctly identified that 2027 is indeed next year. The article’s dry "And for having passed such a high bar, perhaps that’s why it’s been crowned as the new leader in the AI race. Congratulations," drips with well-deserved sarcasm. In the cutthroat "AI race," where every new model release is accompanied by breathless pronouncements of superiority, Gemini 3’s ability to correctly state the upcoming year becomes, ironically, a notable achievement simply because its competitors failed. This highlights the often-inflated rhetoric surrounding AI progress versus the practical, sometimes underwhelming, reality of these systems. While Gemini 3’s success on this specific query is a positive sign for Google’s newer models, it doesn’t erase the broader concerns raised by the AI Overview’s persistent failures or the initial stumbles of other leading chatbots. The competitive landscape pushes companies to deploy AI features rapidly, often prioritizing novelty and perceived intelligence over bulletproof factual accuracy. This "move fast and break things" mentality, while common in tech, becomes problematic when the "things" being broken are fundamental facts and user trust.
In conclusion, the simple question of "what year is next year" has inadvertently exposed a profound and persistent vulnerability in some of the most advanced artificial intelligence systems currently deployed. Google’s AI Overview’s consistent failure to grasp this basic temporal fact, coupled with its history of generating outlandish and misleading information, underscores the critical need for greater scrutiny, robust testing, and transparency in AI development and deployment. While other leading models like ChatGPT and Claude demonstrated the capacity for self-correction, Google’s continued propagation of demonstrably false information, even on such a fundamental issue, severely erodes public confidence. The incident serves as a stark reminder that despite their impressive capabilities in language generation and complex problem-solving, current large language models often lack true common sense, real-time factual grounding, and reliable temporal reasoning. The "AI race" may be accelerating, but if the leading contenders cannot even agree on what year it is, then the journey towards truly intelligent and trustworthy AI remains significantly longer and more fraught with challenges than many in the industry care to admit. The ethical responsibility to ensure factual accuracy and prevent the proliferation of confident misinformation rests squarely on the shoulders of AI developers, demanding a shift from a focus on speed and hype to one of precision and reliability.